缘起
近期看公司日志系统,梳理整体流程如下:
- 日志规范
- 日志采集
- 日志清洗
- 原始数据存储
- 主题数据生成
- 报表平台和邮件数据展现
1 属于业务层,每个公司都应该有统一的日志打印规范,为后续清洗、主题数据生成才可能统一。
2、3、4属于基础能力平台,每个业务都需要这个基础能力将原始数据存储到大数据平台。
数据采集
日志实时分析,很多人都会想到基于很火的ELK Stack(Elastic/Logstash/Kibana)来搭建。ELK方案开源,在社区中有大量的内容和使用案例。
Logstash作为基础数据采集、过滤、数据加载组件,Elastic作为数据存储基础组件,Kibana作为主题数据展示使用。
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的 “存储库” 中。(我们的存储库当然是 Elasticsearch。)
Logstash是elastic提供的日志收集、过滤、处理软件,配合hadoop、elasticSearch可以搭建日志监控平台。
官方地址:
https://www.elastic.co/products/logstash
特性:
实时性高,支持分布式。
社区成熟,上下游支撑软件多,中文社区:https://elasticsearch.cn/。
场景
搭建分布式实时日志处理平台。
存储层使用elastic search可以提供日志采集、处理、存储、查询整体解决方案。
搭配流式处理消息框架可以搭建报警平台。
同类工具
Scribe
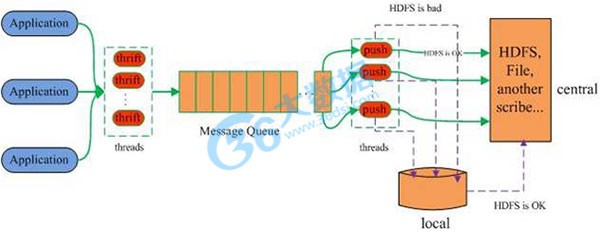
Scribe是Facebook开源的日志收集系统,在Facebook内部已经得到大量的应用。它能够从各种日志源上收集日志,存储到一个中央存储系统(可以是NFS,分布式文件系统等)上,以便于进行集中统计分析处理。它为日志的“分布式收集,统一处理”提供了一个可扩展的,高容错的方案。当中央存储系统的网络或者机器出现故障时,scribe会将日志转存到本地或者另一个位置,当中央存储系统恢复后,scribe会将转存的日志重新传输给中央存储系统。其通常与Hadoop结合使用,scribe用于向HDFS中push日志,而Hadoop通过MapReduce作业进行定期处理。
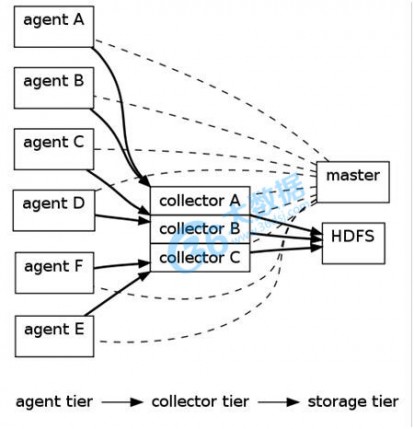
Scribe的系统架构:
Flume
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
Flume提供了从console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog日志系统,支持TCP和UDP等2种模式),exec(命令执行)等数据源上收集数据的能力。
当前Flume有两个版本Flume 0.9X版本的统称Flume-og,Flume1.X版本的统称Flume-ng。由于Flume-ng经过重大重构,与Flume-og有很大不同,使用时请注意区分。
Cloudera Flume构架: